Prefix Searching
What is Prefix Search?
Prefix search is a method for quickly finding all entries in a dataset that share a common prefix. In the context of geohashes, it allows us to retrieve all geohashes that start with the same characters, which is useful for geographical proximity searches.
Trie Tree
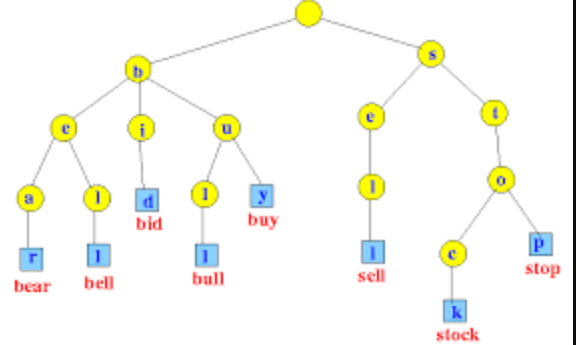
We can store Geohashes in a Trie Tree data structure. Tries enable us to efficiently retrieve geohashes with a common prefix in O(L) time, where L is the length of the prefix being searched.
Key Features of Trie Tree:
- Efficient Retrieval: Quickly find geohashes sharing a common prefix.
- Time Complexity:
O(L), whereLis the prefix length.
Patricia Trie
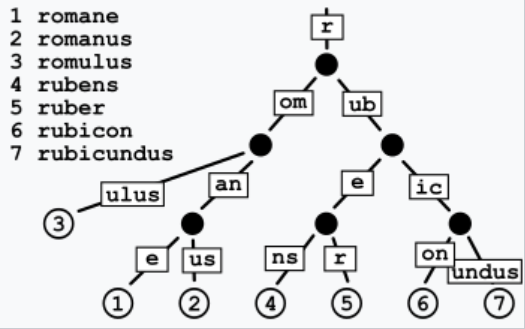
A Patricia Trie, also known as a Radix Tree, is a type of Trie Tree that optimizes space by merging common prefixes into single nodes. This further enhances the efficiency of prefix searching by reducing the number of nodes.
Key Features of Patricia Trie Tree:
- Space Optimization: Merges common prefixes to save space.
- Efficient Lookup: Retrieves geohashes with common prefixes efficiently.
- Time Complexity: Best case
O(log N)whereNis the length of the longest geohash stored, and worst caseO(L)whereLis the length of the prefix.
Comparisons
Skip List
A Skip List is a probabilistic data structure that allows for fast search, insertion, and deletion operations. It consists of multiple levels of linked lists, with each higher level acting as an "express lane" for elements lower down.
-
Pros:
- Efficient Average-case Performance: Provides good average-case performance for search operations, typically
O(log N)time complexity. - Cache-friendly: The contiguous arrangement of nodes makes Skip Lists more cache-friendly than tree-based structures.
- Efficient Average-case Performance: Provides good average-case performance for search operations, typically
-
Cons:
- Space Overhead: Requires additional space to maintain pointers for multiple levels, resulting in higher space usage compared to a Patricia Trie.
- Probability Calculations: Maintaining balance requires careful calculation of node levels' probabilities, involving some understanding of probability theory.
B-Trees and MemTables
B-Trees are balanced tree data structures that maintain sorted data and enable searches, sequential access, insertions, and deletions with logarithmic time complexity. MemTables are in-memory data structures used in conjunction with B-Trees to facilitate efficient storage and retrieval of key-value pairs before persisting data to disk.
-
Pros:
- Efficient Disk-based Storage: Ideal for managing large datasets and effective for disk-based storage solutions.
- Range Queries and Sorted Data Retrieval: Provides excellent performance for range queries and retrieving sorted data efficiently.
-
Cons:
- Memory Usage: MemTables require significant memory to store data before flushing to disk, which can be a limitation for very large datasets.
- Complexity in Merging: Managing and merging data between MemTables and disk-based storage can introduce complexity and overhead in maintaining data consistency.
Why Patricia Trie?
For geospatial data, where object locations might change frequently, in-memory solutions like Patricia Trie are preferred. They offer superior speed and efficiency in managing dynamic data, avoiding the latency associated with disk I/O operations.